반응형
문제점
bs4와 requests module을 사용해서 local에서는 문제없이 크롤링이 됬었는데 heroku server에서 실행을 시키니 response.status_code의 값이 418이 나왔다.
해결방법
이 문제를 해결하기 위해서 두가지를 설정하였다.
1. 정확한 url 입력하기
opgg 사이트를 크롤링하였는데 "https://op.gg/~"으로 url을 설정하여서 requests를 보냈었다. 이렇게 하니 로컬에서는 제대로 됬었는데 heroku 서버에서는 작동하지 않았다. 그래서 정확한 url인 "https://www.op.gg/~"으로 바꾸니 정상적으로 크롤링이 됬다.
2. Header 추가하기
해당 웹사이트가 python crawl을 anti-climbing program이라고 판단하여서 418 error을 return하는 것이다. 이를 피하기 위해서는 요청을 보낼 때 header를 추가해서 보내면 된다. User-Agent를 추가해야 하는데 해당 브라우저에서 F12를 눌러 관리자도구를 킨다. 관리자도구 탭에서 네트워크에 들어간다. 아무 요청이나 들어가서 Headers에 Resquest-Headers를 보면 User-Agent가 있다.
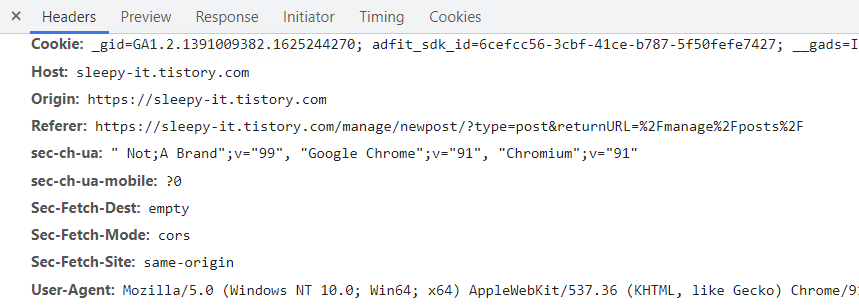
"Mozilla/5.0 ~~"이 부분이 User-Agent이고 이를 Header에 추가해서 보내면 된다.
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:90.0) Gecko/20100101 Firefox/90.0'}
response = requests.get(url, headers=header)이런식으로 header를 추가해서 requests를 보내면 정상적으로 reponse가 온다.
반응형


댓글